%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Diffusion model
Diffusion As Shader
Diffusion as Shader (DaS) is an innovative video generation control model designed to achieve diverse control over video generation through a 3D perception diffusion process. This model utilizes 3D tracking videos as control inputs, supporting multiple video control tasks under a unified architecture, including mesh-to-video generation, camera control, motion transfer, and object manipulation. The main advantage of DaS lies in its 3D perception capabilities, significantly enhancing the temporal consistency of generated videos and demonstrating powerful control abilities with minimal data and short tuning times. Developed collaboratively by research teams from institutions like the Hong Kong University of Science and Technology, the model aims to advance video generation technology, providing more flexible and efficient solutions for fields such as filmmaking and virtual reality.
Video Production
57.7K

Dynamiccontrol
DynamicControl is a framework designed to enhance the control of text-to-image diffusion models. It dynamically combines various control signals and supports adaptive selection of different numbers and types of conditions to synthesize images more reliably and in detail. The framework first utilizes a dual-loop controller, employing pre-trained conditional generation and discriminator models to generate initial real score rankings for all input conditions. Then, a multimodal large language model (MLLM) constructs an efficient condition evaluator to optimize the condition ordering. DynamicControl jointly optimizes MLLM and the diffusion model, leveraging the inference capabilities of MLLM to facilitate multi-condition text-to-image tasks. The final ordered conditions are input into a parallel multi-control adapter to learn dynamic visual condition feature maps and integrate them to adjust ControlNet, enhancing control over the generated images.
AI Model
47.7K
Stable Diffusion 3.5 Large Turbo
Stable Diffusion 3.5 Large Turbo is a multi-modal diffusion transformer (MMDiT) model for text-to-image generation, employing Adversarial Diffusion Distillation (ADD) technology to enhance image quality, layout, understanding of complex prompts, and resource efficiency, with a particular focus on reducing inference steps. This model excels in image generation, capable of understanding and generating complex text prompts, making it suitable for various image generation scenarios. It is published on the Hugging Face platform under the Stability Community License, allowing for free use by researchers, non-commercial use, and organizations or individuals with annual revenue under $1 million.
Image Generation
69.6K
TCAN
TCAN is a novel human character animation framework based on diffusion models that maintains temporal consistency and generalizes well to unseen domains. The framework ensures that generated videos maintain the original image's appearance while adhering to the posture of the driving video and maintaining background consistency through unique modules such as the Appearance-Posture Adaptation Layer (APPA), temporal control networks, and posture-driven temperature maps.
AI video generation
97.7K
Hallo
Hallo, a portrait image animation technology developed by Fudan University, utilizes diffusion models to generate realistic and dynamic portrait animations. Unlike traditional methods relying on parametric models for intermediate facial representations, Hallo adopts an end-to-end diffusion paradigm and introduces a hierarchical audio-driven visual synthesis module to enhance the alignment precision between audio input and visual output, including lip, facial expression, and pose movements. This technology offers adaptive control over facial expression and pose diversity, enabling more effective personalized customization for individuals of different identities.
AI image generation
152.6K
Fresh Picks
Musev
MuseV is a diffusion model-based virtual human video generation framework that supports the generation of unlimited length videos. It utilizes a novel visual conditional parallel denoising approach. It provides a pre-trained virtual human video generation model, supporting functionalities like Image2Video, Text2Image2Video, and Video2Video. MuseV is compatible with the Stable Diffusion ecosystem, including base models, LoRA, ControlNet, and more. It supports multi-reference image techniques such as IPAdapter, ReferenceOnly, ReferenceNet, and IPAdapterFaceID. MuseV's strength lies in its ability to generate high-fidelity, unlimited length videos, specifically targeting the video generation domain.
AI video generation
440.2K
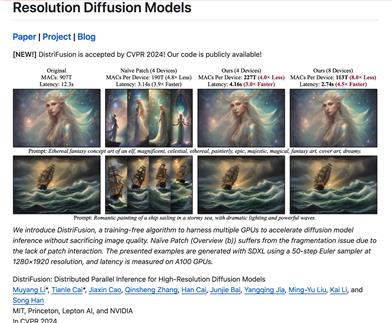
Distrifusion
DistriFusion is an algorithm that requires no training and takes advantage of multiple GPUs to accelerate diffusion model inference without compromising image quality. DistriFusion can reduce delay based on the number of devices used while maintaining visual fidelity.
AI image generation
75.9K

Sora
AI video generation
17.0M
Diffusionmat
DiffusionMat is a novel image matting framework that uses a diffusion model to transform rough to fine alpha matting. Unlike traditional methods, our approach treats image matting as a gradual learning process, starting from adding noise to the trimmed map and iteratively denoising through a pre-trained diffusion model, gradually guiding the prediction towards a clean alpha matting. A key innovation in our framework is a correction module, which adjusts the output in each denoising step to ensure that the final result aligns with the structure of the input image. We also introduce Alpha Reliability Propagation, a novel technique aimed at maximizing the utility of available guidance by selectively enhancing the alpha information in the trimmed map regions with confidence, thus simplifying the correction task. To train the correction module, we have designed a specific loss function to target the accuracy of alpha matting edges and the consistency of opaque and transparent areas. We have evaluated our model on several image matting benchmarks, and the results show that DiffusionMat always outperforms existing methods.
AI Image Editing
70.4K
Graphmaker
GraphMaker is a diffusion model designed for generating large property graphs. It can generate both node attributes and graph structures simultaneously, or generate node attributes first and then the graph structure. Supported datasets include cora, citeseer, amazon_photo, and amazon_computer. You can leverage pre-trained models to generate graphs.
AI Model
52.4K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
45.5K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.3K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
44.2K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
43.6K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
43.6K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.7K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M